Introduction
Once a large language model is released, updating its behavior is often slow, costly, or impossible. Training-time alignment encodes safety, privacy, fairness, and factuality objectives into the parameters themselves, but deployment introduces context-specific risks that cannot all be anticipated in advance: changing policies, user-specific constraints, retrieval contamination, adversarial prompting, and jurisdiction-dependent requirements. Inference-time methods address this gap. They regulate model behavior at runtime, after training has concluded, by acting on the generation pipeline rather than on the parameters.
This work reviews the field as a single coherent control plane. Drawing on 230+ papers published between 2020 and 2026, we organize seven categories of inference-time methods into three tiers—External Controls (Context Engineering, Guardrails, Decoding Strategies), Internal Manipulations (Representation Engineering, Unlearning, Pruning), and System-Level Orchestration (Multi-Agent Systems)—and analyze each across four trustworthiness dimensions: safety, privacy, fairness, and factuality. Figure 1 shows the taxonomy and the points at which each tier attaches to the generation pipeline.
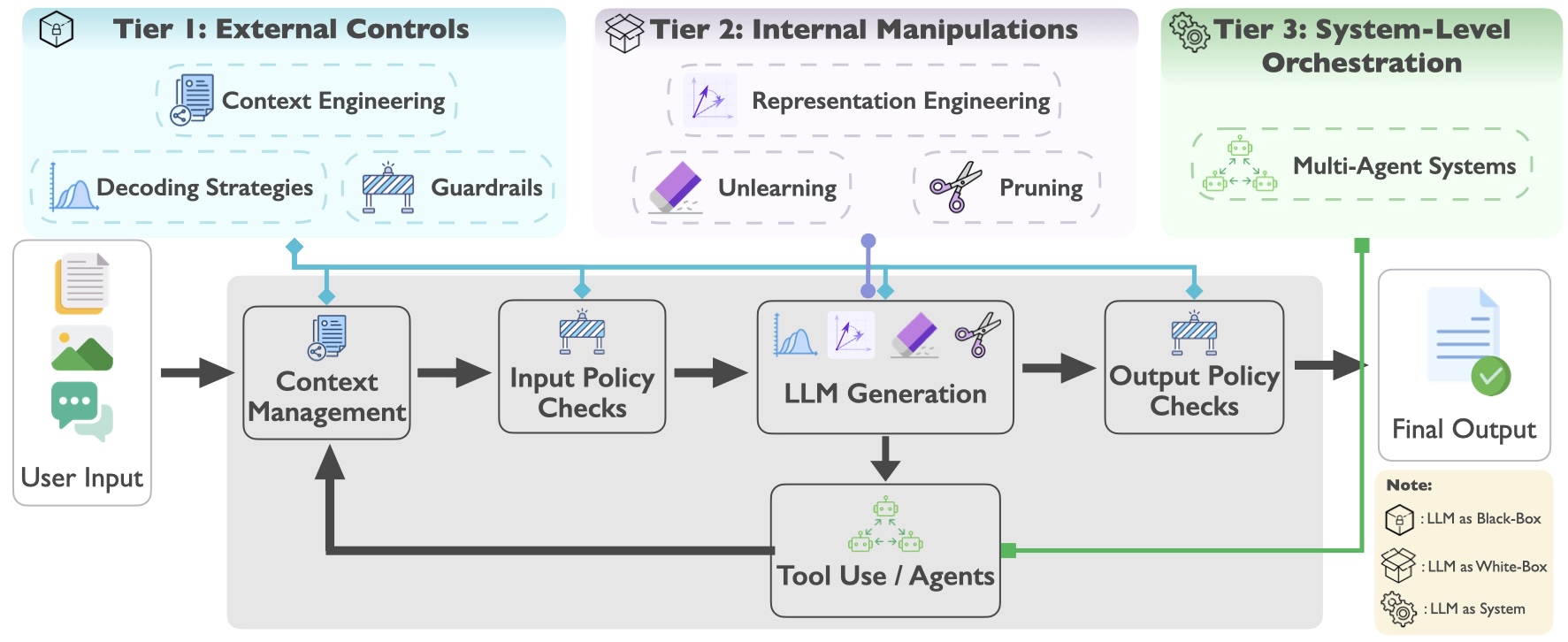
The companion repository at github.com/leopoldwhite/Awesome-Inference-Time-Trustworthiness indexes more than 230 papers organized by these seven categories, with arXiv links and code references where available. The remainder of this page summarizes each tier with the corresponding figures from the paper, the meta-axis evaluation framework we adopt, a comparison with related work, and the open challenges we identify.
Tier 1: External Controls
External controls treat the model as a black box. They shape behavior by modifying inputs, the decoding process, or outputs, without accessing or modifying internal weights or activations. These methods are the most modular and widely applicable: they require no white-box access and can be deployed on proprietary, API-only models. In the pipeline they attach to the context-assembly, input/output policy check, and decoding stages.
The most modular and widely applicable layer—but also the easiest to bypass once an adversary adapts.
Context Engineering
Strategic prompt design, retrieval, and context shaping. Methods in this category guide outputs through rules, instructions, exemplars, retrieval-augmented context, or memory windows—without changing model parameters. The 32 papers we cover include prompt-based safety (e.g., system-prompt jailbreak defenses), retrieval-augmented factuality (Self-RAG, Chain-of-Verification), in-context fairness mitigation, and privacy-preserving inference (InferDPT).
Guardrails
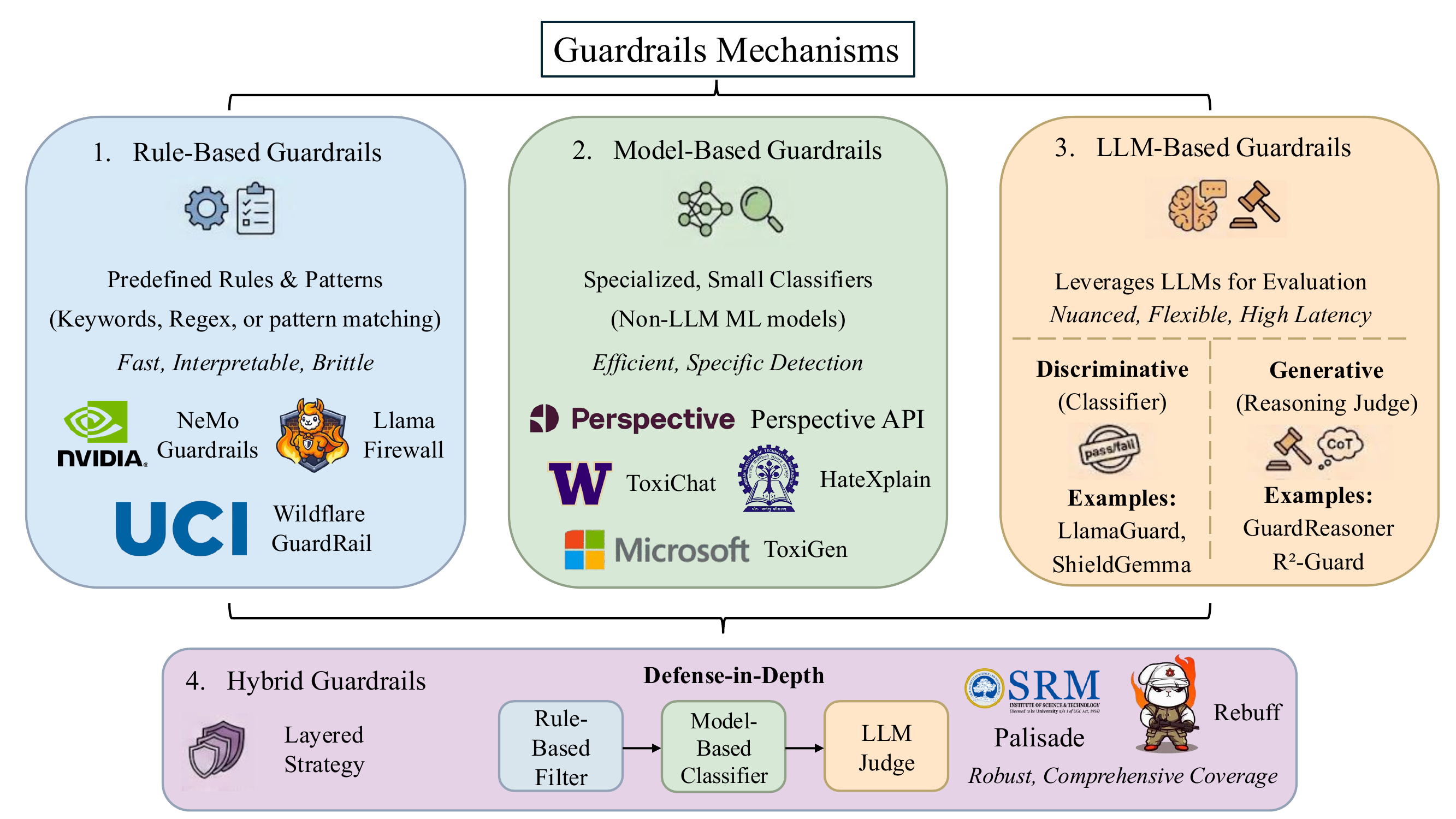
External modules that inspect inputs or outputs against safety or policy constraints, blocking, redacting, or regenerating content when violations occur. Figure 2 organizes the design space into four mechanism types: rule-based (NeMo Guardrails, Llama Firewall), model-based classifiers (Perspective, ToxiChat), LLM-based judges—split between discriminative (LlamaGuard, ShieldGemma) and generative reasoning judges (GuardReasoner, R²-Guard)—and hybrid defense-in-depth pipelines that compose the previous three.
Decoding Strategies
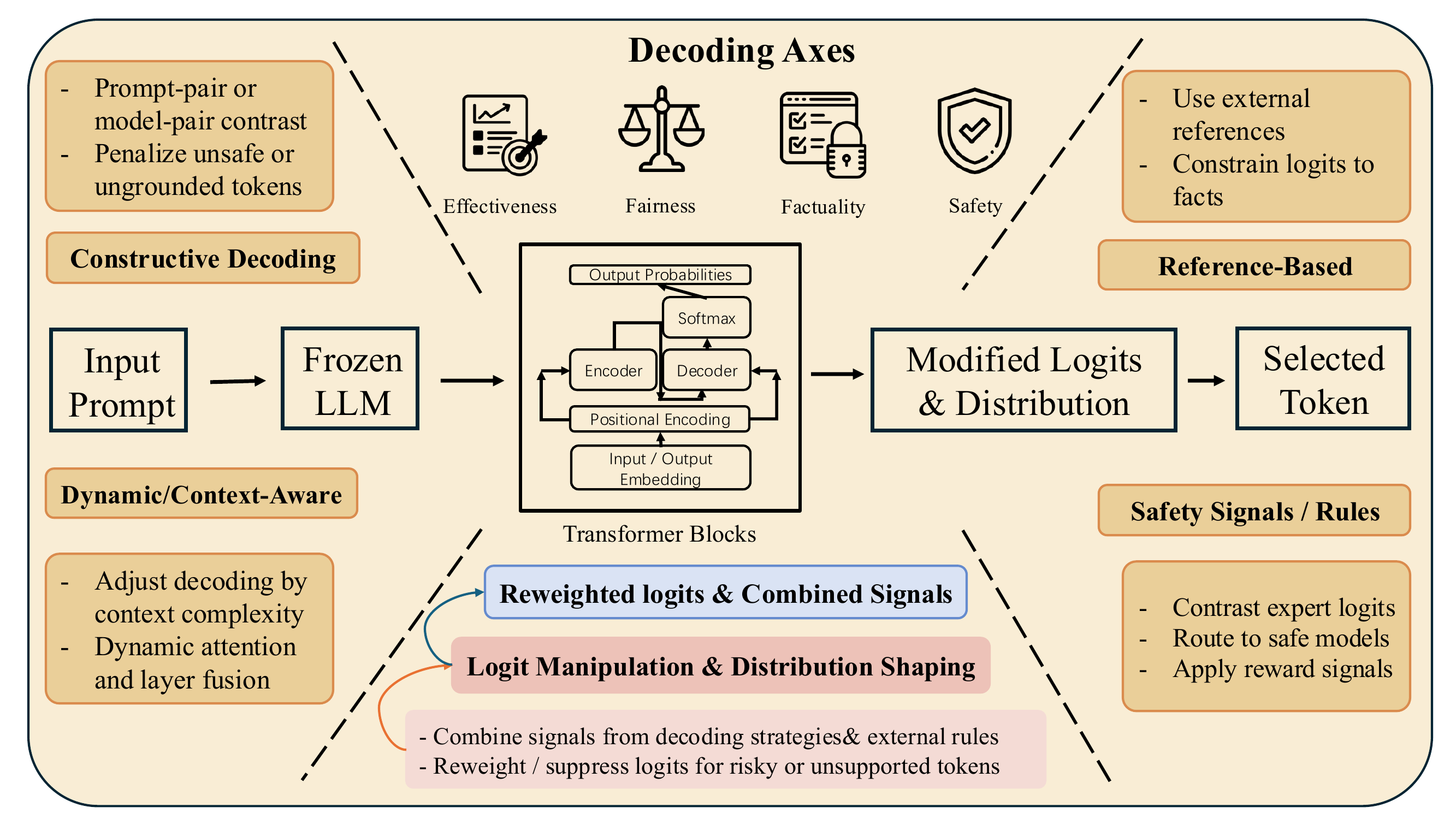
Manipulation of token-level distributions during generation to promote desired attributes or suppress undesired ones. Figure 3 plots the design axes—constructive decoding (prompt- or model-pair contrast), dynamic / context-aware decoding, and reference-based decoding—against four trustworthiness targets, with the central pipeline showing how logits are reweighted, combined, and routed to safe or contrastive experts.
Tier 2: Internal Manipulations
Internal manipulations require white-box access. They intervene directly in the model's computation—modifying activations during a forward pass, suppressing targeted behavior or knowledge, or removing architectural components. Compared with external controls they offer finer-grained, more persistent behavioral changes, at the cost of needing access to representations or weights.
Finer behavioral control at the cost of weights and activations —and a verification problem we cannot yet solve.
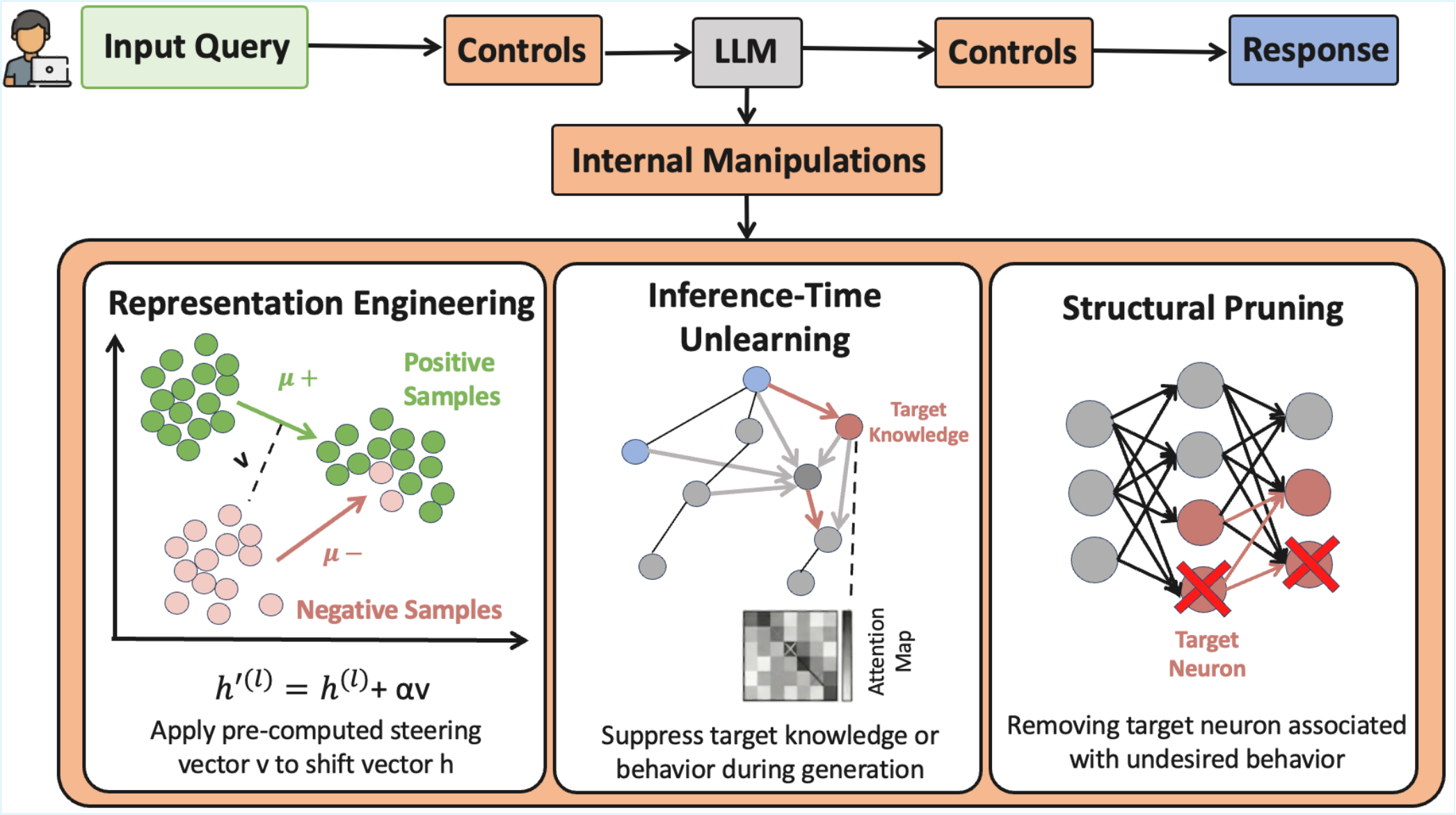
Three categories share this tier (Figure 4): Representation Engineering shifts hidden states along pre-computed concept vectors, treating activations as controllable objects; Inference-Time Unlearning suppresses target knowledge or behavior at generation time through attention masking, activation gating, or in-context refusal triggers; Structural Pruning removes weights, neurons, or attention heads associated with unsafe or biased behavior, exposing the alignment fragility of the underlying network.
Tier 3: System-Level Orchestration
At the system level, trustworthiness becomes an emergent property of structured interaction among multiple agents rather than a property of any single model. Multi-agent systems coordinate LLMs through debate, cross-verification, role specialization, and iterative self-correction. The tool-use / agents loop spans context assembly, generation, and output checking, creating feedback cycles that enable collective reliability.
Trustworthiness as an emergent property of structured interaction —not a property of any single model.
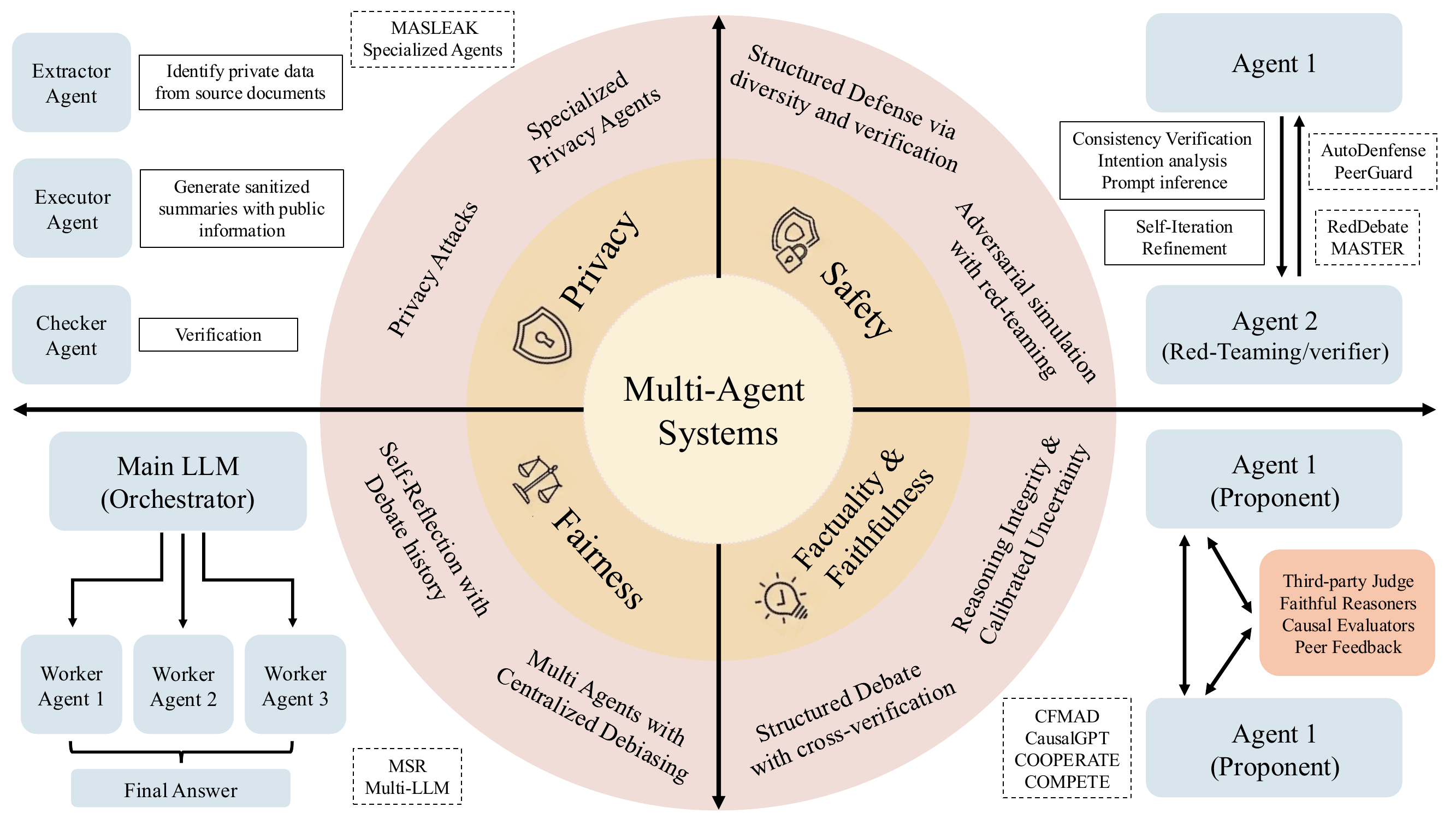
Figure 5 cuts the design space by trustworthiness dimension: safety via role-diverse defenses and adversarial red-teaming (AutoDefense, PeerGuard, RedDebate, MASTER); factuality and faithfulness via structured debate with cross-verification and calibrated uncertainty (CFMAD, CausalGPT, COOPERATE/COMPETE); fairness via centralized debiasing with self-reflection (MSR, Multi-LLM); and privacy via specialized agents (Extractor, Executor, Checker; MASLEAK).
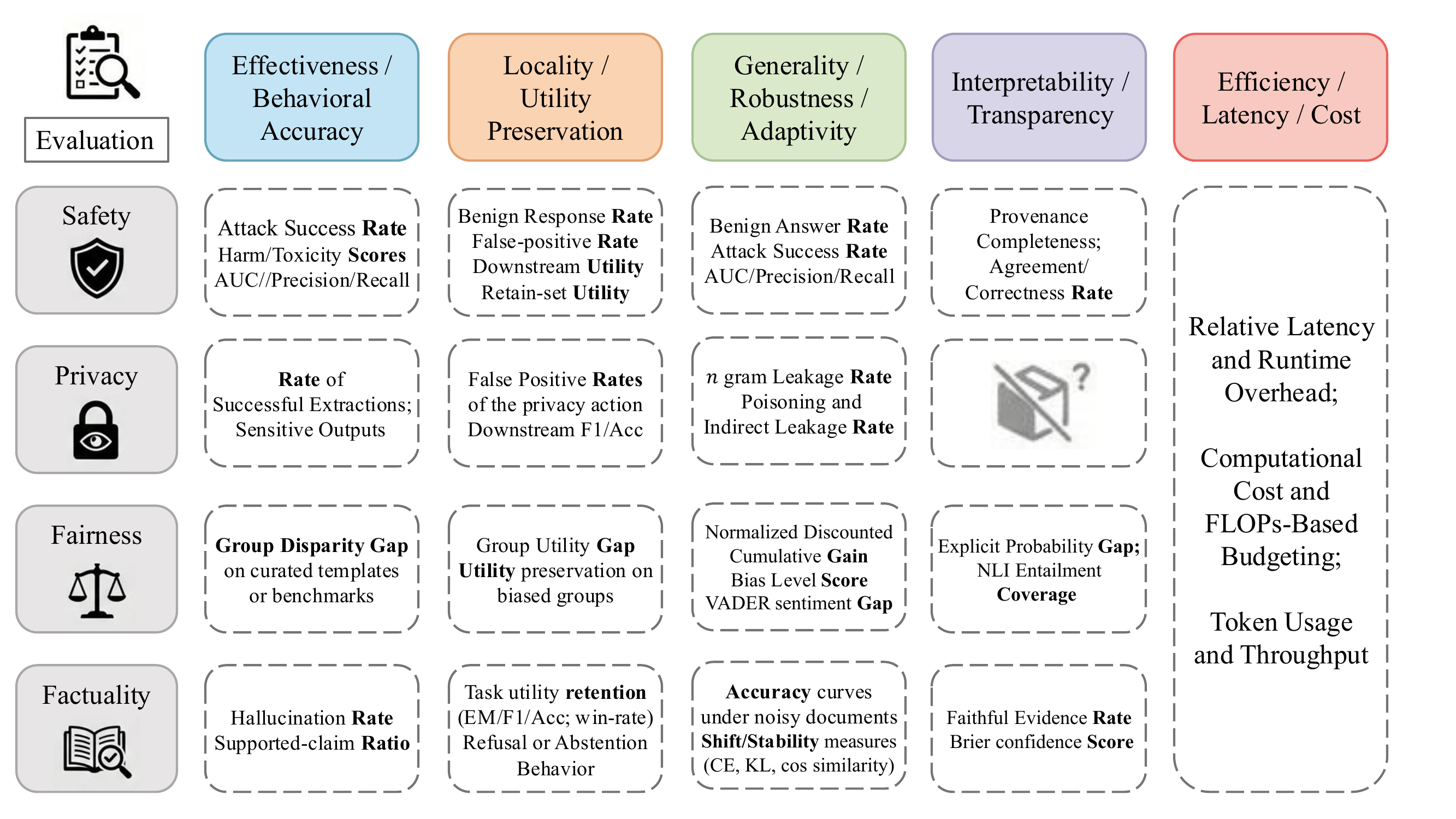
Evaluation
Inference-time methods differ greatly in where and how they intervene —in prompts, in logits, in activations, in external filters, or in the surrounding workflow. As a result evaluation cannot be unified by one benchmark or one metric family. We adopt a meta-axis evaluation view (Figure 6): rows are the four trustworthiness dimensions (Safety, Privacy, Fairness, Factuality), columns are five complementary evaluation axes (Effectiveness / Behavioral Accuracy, Locality / Utility Preservation, Generality / Robustness / Adaptivity, Interpretability / Transparency, Efficiency / Latency / Cost), and each cell lists representative metrics specific to the dimension–axis intersection.
Open Challenges
Inference-time methods make trustworthiness modular and updatable, but each tier still leaves open problems. The paper discusses these and outlines directions for future work; we group them into four cross-cutting themes.
The frontier is not the next defense—it is making any defense verifiable, composable, and stable under adversaries we have not yet seen.
- Brittleness under adaptive adversaries. Static guardrails and decoding constraints fail against adaptive jailbreaks; representation steering and unlearning can be reversed by adversarial probing. Robust deployment will require periodically re-evaluated, adaptive defenses rather than fixed thresholds.
- The control–utility tradeoff. Stricter inference-time controls reduce helpfulness, fluency, or accuracy. Standardized benchmarks that explicitly trace the trust–utility Pareto frontier—rather than reporting a single operating point—are still missing.
- Verification of removal. Unlearning, pruning, and editing can suppress information without truly erasing it, leaving models vulnerable to recovery under adversarial probing. The lack of formal removal guarantees blocks deployment in privacy-critical and regulatory settings.
- Composition and emergent risk. How interventions interact when layered together is poorly understood. Multi-agent orchestration introduces novel failure modes such as group-think, cascading hallucinations, and amplified jailbreaks via the very debate channels intended to improve reliability.
🔔 News
- 2026-05 Paper available on preprints.org (DOI: 10.20944/preprints202605.1041.v1).
📚 Cite
BibTeX entry for the preprint version (DOI: 10.20944/preprints202605.1041.v1).
@article{bai2026inferencetime,
title = {Inference-Time Control for Trustworthy Large Language Models},
author = {Bai, Yuyang and Liu, Zheyuan and Yan, Han and Xu, Zhangchen and Wan, Yixin and Chen, Canyu and Wang, Zehong and Yuan, Xiangchi and Huang, Yue and Dou, Guangyao and Zhang, Yuji and Zhu, Hangxiao and Li, Zhuofeng and Li, Manling and Zhang, Xiangliang and Bansal, Mohit and Koyejo, Sanmi and Chang, Kai-Wei and Zhang, Yu and Jiang, Meng},
journal = {Preprints},
year = {2026},
month = {May},
publisher = {Preprints},
doi = {10.20944/preprints202605.1041.v1},
url = {https://doi.org/10.20944/preprints202605.1041.v1}
}
📁 Repository
The companion repository hosts the full paper list (over 230 entries across the seven method categories), with arXiv links and code references where available. We welcome issues and pull requests for omissions.